Unlike Bitcoin, Ethereum mining requires a large amount of RAM. The “appetite” for this currency grows as new records are added to the blockchain. Miners with outdated video cards are increasingly faced with " CUDA error 11" This error means that the size of the Ethereum Dag file has exceeded the memory buffer capacity of the mining program. In some cases, the error occurs due to a failure of the mining software and can be eliminated without upgrading the hardware. Let's figure out what a DAG file is and what its size depends on.
What is a dag file
To find a block signature (hash) using the Ethash algorithm, a block of data called a DAG file is used. It is stored in the video card memory while the miner is running. The algorithm is designed in such a way that after finding 30 thousand blocks, the size of the Ethereum DAG file (as well as other cryptocurrencies based on the Ethash algorithm) increases by 8 megabytes. Each new state is called an epoch.
The speed of changing “epochs” depends on the time the block is located, which for Ethereum ranges from 10 to 60 seconds. The average is 14.5 seconds . At the time of writing, 6249979 Ethereum has been mined, which means epoch 208. The DAG file size is 2.62 gigabytes. Ethereum Classic, whose blocks are closed a little faster, is already in epoch 215. Therefore, its DAG file takes up 2.68 gigabytes of video memory. You can find out the current era and file size for Ethash-based cryptocurrencies in the DAG-file calculator section of the investoon.com website.
Ethereum DAG file size
The DAG file size is dynamic and is constantly increasing. As mentioned above, every 4-5 days it increases by 8 MB. To determine the size of the DAG, use the following:
- the GPU-Z program at the time of mining, which allows you to track the actual size of the equipment memory and file size;
- you can find the document you are looking for on your computer and find out its parameters;
- seek help from the resources https://investoon.com/tools/dag_size or https://minerstat.com/dag-size-calculator?lang=ru, where the information is updated in real time.
Important: The website method is considered the most convenient due to the frequency of updates, real-time reference, and the DAG size calculator. It is enough to enter the desired block and find out what the volume will be after n-amount of time, what is the current era of Ethereum, etc.
The table below shows how the DAG file has changed in recent years and what to expect in the future:
| DAG size | era | Block | Day |
| 1.99 GB | 127 | 3,839,999 | September 9, 2017 |
| 2.99 GB | 256 | 7,679,999 | May 2, 2019 |
| 3.99 GB | 383 | 11,519,999 | December 22, 2020 |
| 5.99 GB | 639 | 29,199,999 | April 6, 2024 |
| 7.99 GB | 895 | 26,879,999 | July 21, 2027 |
| 10.99 GB | 1280 | 38,399,999 | July 26, 2032 |
If the PoW algorithm is not changed to PoS before the 100 millionth block, then the DAG size will be 27.04 GB during epoch 3333.
Where is the Ethereum DAG file located?
Ethereum's DAG file is generated by the mining application according to a predefined algorithm. After starting the program, it is loaded into the RAM of each video card in the farm. The size of the Ethereum DAG file can be seen using the GPU-Z utility, which displays the current performance of video adapters, including video memory load. This indicator is displayed in the Memory Usage line.
How to Delete Etherium DAG File
To delete a DAG-file in Windows, you must enable the display of hidden folders and files in the Explorer settings and view the directory of the current user. Ethminer and Qtminer programs by default store the DAG file in the AppData/Local/Ethash . File names begin with "full-R23".
To remove it, you need to close the mining application and empty the directory.
Important: the next time you start the miner, the files will be generated anew and this will take a lot of time.
Today we’ll look at how to simplify the work of a data engineer in Apache AirFlow by automating the process of creating DAGs from one or more Python files. Using practical examples, we will analyze the advantages and disadvantages of 5 methods of dynamic generation, as well as the features of scaling Big Data pipelines.
What is dynamic DAG generation in Apache Airflow and why is it needed?
In the article about the best practices for developing Big Data pipelines in Apache Airflow, we mentioned the DRY principle (Don't Repeat Yourself). For example, many ELT processes with different data sources and sinks often contain a lot of the same Python code. In order not to write this manually every time, it is advisable to generate this Python code automatically in the form of a DAG (Directed Acyclic Graph) - a directed acyclic graph of data processing tasks [1].
Airflow runs all Python code in the DAG_FOLDER folder and loads all DAG objects that appear in the globals() function. Recall that Python's globals() function returns variables that the user can set and retrieve values, just like a dictionary. After setting the values, you can call the variables as if they were created normally [2].
So the easiest way to create a DAG is to write it as a static Python file. But creating a DAG manually is not always practical. For example, when there are hundreds or thousands of DAGs that do similar things, changing only a few parameters. Or you need a set of DAGs to load tables that can change. In these and many other cases, dynamically creating a DAG will help.
Since everything in Airflow is code, you can dynamically create DAGs using only Python. By creating a DAG object in the globals() function using Python code in the DAG_FOLDER folder, Airflow will load it. Dynamic generation of Directed Acyclic Graph is possible in several ways, which can be grouped by the number of Python files used, which we will consider next [3].
3 ways to dynamically generate DAG from one file
So, the first way to dynamically create a Directed Acyclic Graph is to have a single Python file that generates a DAG based on input parameters, such as a list of APIs or tables like in an ETL/ELT pipeline with multiple data sources or sinks. This requires creating multiple Directed Acyclic Graphs using the same template. The advantages of this method are the following [3]:
- simple implementation;
- the ability to accept input parameters from different sources;
- speed – adding DAG files occurs almost instantly, because To do this, you just need to change the input parameters.
However, this method also has disadvantages:
- The Directed Acyclic Graph file itself is not created;
- you need to have a Python file in the DAG_FOLDER folder and code generation will occur on every scheduler heartbeat, which can cause performance problems when there are a large number of DAGs or connecting to an external system, such as a DBMS.
The single-file method is implemented differently depending on what input parameters are used to create the DAG [3]:
- The Create_DAG method is a custom Python function that will generate a DAG based on an input parameter. Input parameters can come from any source that the Python script can access. Optionally, you can set up a simple loop to generate unique parameters and pass them to the global scope, registering them as valid DAGs in the Airflow scheduler.
- generating DAG from variables. Input parameters do not need to exist in the Directed Acyclic Graph file itself; their values can be set in a Variable object. To get this value, you need to import the Variable class and pass it to the appropriate scope. To ensure that the interpreter registers this file as valid regardless of whether the variable exists, default_var is set to 3.
- generating DAGs from connections is a great option if each DAG connects to a DBMS or API. Since the data engineer will have to configure these connections anyway, creating a Directed Acyclic Graph from this source will avoid redundant work. To implement this method, you must retrieve connections from the Airflow metadatabase by creating a Session instance and querying the Connection table. You can filter this query so that it retrieves only connections that meet certain criteria. You need to access the Models library to work with the Connection class, and you need access to the Session class to query the current database session.
Multi-file methods
You can also use multiple Python files to dynamically generate a Directed Acyclic Graph, so that for each created DAG there is a separate Python file in the DAG_FOLDER folder. This is especially useful in production, where a Python script generates DAG files when running a CI/CD workflow. DAGs are created during a CI/CD build and then deployed to Airflow. There may also be another Directed Acyclic Graph that runs this generation script periodically.
The main advantages of this method:
- better scalability compared to single-file methods, because there is no need to parse the code in DAG_FOLDER and the DAG generation code is not executed at every scheduler heartbeat;
- DAG files are explicitly created before deployment to Airflow and have full code visibility.
The main disadvantage of this method is the complexity of setup. Additionally, changes to existing DAGs or additional Directed Acyclic Graphs are created only after the script is run, which may require a full deployment.
The following methods will help you implement the method of dynamically generating DAG from several files:
- creating a DAG from JSON configuration files using a Python script. This option is relevant for data analysts who need to schedule different SQL queries for the same data sources, running at different times. To do this, you first need to create a template file with a DAG structure and variables, information about which will be dynamically generated, for example, dag_id, scheduletoreplace and querytoreplace. Next, you need to create a dag-config folder with a JSON configuration file for each DAG. The configuration file defines the necessary parameters: dag_id, scheduletoreplace and querytoreplace. Finally, create a Python script that will create DAG files based on the template and configuration files, looking through each configuration file in the dag-config/ folder and overwriting the parameter values. To generate DAG files, you can run this ad-hoc script as part of a CI/CD workflow, or you can create another DAG to run the script periodically. This simple example of generating a DAG from one template can be expanded to include dynamic inputs for tasks, dependencies, various statements, etc.
- DAG Factory ( DAG-factory) – An open source Python library for dynamically generating Airflow DAG files from YAML files. Developed by a community of enthusiasts, it is available for free download from Github [4] . To use dag-factory, you must install this package in the Airflow environment and create YAML configuration files to generate the Directed Acyclic Graph. You can then dynamically create a Directed Acyclic Graph by calling the dag-factory.generate_dags() method in a Python script. Read how this idea is implemented in practice in our next article.
Dynamic DAG generation and AirFlow scalability
Depending on the number of DAGs, Airflow's configuration, and the infrastructure on which it is deployed, dynamically creating a Directed Acyclic Graph may cause performance issues when scaling. Therefore, the data engineer is recommended to consider the following aspects [3]:
- Any code in the DAG_FOLDER folder will be executed on every scheduler heartbeat. Therefore, single-file DAG generation methods are likely to cause performance issues when scaled up.
- if the Directed Acyclic Graph parsing time, i.e. code in the DAG_FOLDER folder is greater than the scheduler heartbeat interval, the Sheduler may become blocked and tasks will not be executed.
These performance issues can be addressed by upgrading to Airflow version 2.0, which supports high scheduler availability. But still, the data engineer will need to further optimize the pipelines depending on the operating scale. There is no one-size-fits-all way to implement or scale dynamically generated DAGs, but Airflow's flexibility allows you to find a solution that fits your specific scenario [3].
You will learn more about using Apache AirFlow to develop complex big data analytics pipelines with Hadoop and Spark in specialized courses in our licensed training and development center for developers, managers, architects, engineers, administrators, Data Scientists and Big Data analysts in Moscow:
- Data Pipeline on Apache Airflow and Apache Hadoop
- Data pipeline on Apache AirFlow and Arenadata Hadoop
View schedule
Sign up for a course
Sources
- https://towardsdatascience.com/data-engineers-shouldnt-write-airflow-dags-b885d57737ce
- https://flavio-mtps.medium.com/making-use-of-python-globals-to-dynamically-create-airflow-dags-124e556b704e
- https://www.astronomer.io/guides/dynamically-generating-dags
- https://github.com/ajbosco/dag-factory
How much graphics memory is needed for Ethereum mining?
It should be noted that when displaying a picture on a monitor using a mining video card, it additionally consumes 150-200 megabytes of video memory. In this case, to operate the miner, you will need a GPU with memory larger than the DAG size (DAG file size).
Taking into account the fact that this value of Ethereum has exceeded 2.6 gigabytes, video cards with RAM of 3 GB or more are needed to mine it. Taking into account the constant growth in the size of the FAG file, GPUs with three gigabytes of RAM will lose relevance for broadcasting in 2022. Therefore, for the farm you need to take video cards with at least 4 GB.
Features of selecting a video card in relation to Dag Ether
When choosing a video card, you should pay attention not only to the complexity of the network and hashrate, but also the size of the DAG file.
The fact is that if you buy a card with up to 4 GB of RAM now, it will quickly become unsuitable for ether mining. Using the parameters from the above table of main DAG changes, the profitability and payback of mining should be calculated.
Although the amount of video card memory does not directly affect the hashrate, it should be at least 300-500 MB larger than the size of Doug. The larger the gap between the hardware and file parameters, the better. As the DAG volume approaches the hardware performance, the hashrate gradually drops.
The greatest demand for Ether mining will be for cards with a memory capacity of 6 GB or more , since they should last until 2024. Owners of cards with 3 and 4 GB of RAM should not be upset, because there is still time to mine Ethereum. Accordingly, in May 2022 and December 2022, their equipment will become unsuitable for broadcasting.
It is worth understanding that such cards can be used to mine other coins with the Ethash algorithm, but the purchase for ETH mining will not have time to pay off.
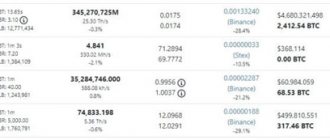
What cryptocurrencies can be mined using the Dagger Hashimoto (Ethash) algorithm and is it profitable?
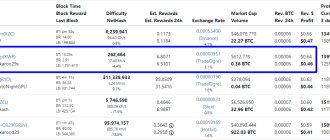
The two most popular Ethash-based cryptocurrencies among GPU farm owners are Ethereum and Ethereum Classic. However, the size of their DAG files does not allow mining on video cards with 2 GB of RAM. In this case, it is worth mining other coins using this algorithm: Expanse , Musicoin , Ubiq or Coilcoin .
Profitability depends on the speed and power consumption of the video card, as well as the price of electricity in your region. You can pre-calculate mining income using the online calculator on Whattomine.com.
Benefits of technology
Despite the disadvantages associated with the obsolescence of mining equipment, the technology of using DAG files has a number of advantages:
- The speed of formation and addition of new blocks to the network.
- Reliability and security of the blockchain.
- Mining Difficulty – Unlike other popular coins, GPU mining remains profitable.
An undeniable advantage is the constant increase in file size . Because of this, over time, both video cards and specialized ASIC miners will “disappear.”
In conclusion, we can say that when choosing equipment and calculating the profitability of Ethereum mining, it is imperative to take into account the dynamics of changes in DAG. Otherwise, you can assemble farms that will soon become unsuitable for Ether mining.
What should owners of RX 5xx or GTX 10xx cards with 4 Gb do?
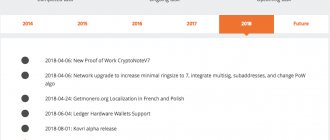
There must be a fly in the ointment: in August, due to the 51% attack on the Ethereum blockchain, the developers decided to reduce the size of the Dag file. The developers of the Ethereum network expressed themselves in detail on their YouTube channel. From the official registry of network development scenarios, at epoch 390 the size of the Ethereum dag file will be changed.