Привет, Хабр! Мы продолжаем наш цикл статьей, посвященный инструментам и методам анализа данных. Следующие 2 статьи нашего цикла будут посвящены Hive — инструменту для любителей SQL. В предыдущих статьях мы рассматривали парадигму MapReduce, и приемы и стратегии работы с ней. Возможно многим читателям некоторые решения задач при помощи MapReduce показались несколько громоздкими. Действительно, спустя почти 50 лет после изобретения SQL, кажется довольно странным писать больше одной строчки кода для решения задач вроде «посчитай мне сумму транзакций в разбивке по регионам». С другой стороны, классические СУБД, такие как Postgres, MySQL или Oracle не имеют такой гибкости в масштабировании при обработке больших массивов данных и при достижении объема большего дальнейшая поддержка становится большой головоной болью.
Собственно, Apache Hive был придуман для того чтобы объединить два этих достоинства:
- Масштабируемость MapReduce
- Удобство использования SQL для выборок из данных.
Под катом мы расскажем каким образом это достигается, каким образом начать работать с Hive, и какие есть ограничения на его применения.
Общее описание
Hive появился в недрах компании Facebook в 2007 году, а через год исходники hive были открыты и переданы под управление apache software foundation. Изначально hive представлял собой набор скриптов поверх hadoop streaming (см 2-ю статью нашего цикла), позже развился в полноценный фреймворк для выполнения запросов к данным поверх MapReduce.
Актуальная версия apache hive(2.0) представляет собой продвинутый фреймворк, который может работать не только поверх фреймворка Map/Reduce, но и поверх Spark(про спарк у нас будут отдельные статьи в цикле), а также Apache Tez.
Apache hive используют в production такие компании как Facebook, Grooveshark, Last.Fm и многие другие. Мы в Data-Centric alliance используем HIve в качестве основного хранилища логов нашей рекламной платформы.
Разгон видеокарт AMD и NVIDIA, основные ошибки
Выполнять разгон желательно, когда установлены обычные значения хешрейт ниже, а потребление электричества выше.
Чтобы оптимизировать работу необходимо перейти в меню рига на третью вкладку Overclocking.
И после этого нажать на кнопку редактирования в конфигурации.
Меню разгона выглядит следующим образом. Параметры для каждой видеокарты отличаются, необходимо искать документацию к каждой или подбирать вручную.
Для карт серии 1080 есть специальная таблетка переключатель. Для видеоадаптеров новее она бесполезна, включать ее не нужно.
Примеры разгона для некоторых популярных карт.
Первичный разгон установлен. Если нужно настроить отельные параметры для каждой карты, то они пишутся через пробел, как указано синим сразу под надписью Default Config в окне разгона.
Настройки обновятся, а установленные значения будут написаны зеленым цветом.
Разгон видеокарт Nvidia такой же, как и в операционной системе Windows, но есть одно существенное отличие. В Hive OS частоты нужно указывать в два раза больше.
Для видеоадаптеров AMD нужно помнить, что лимиты энергопотребления меняются путем подбора. Нужно вручную выбрать оптимальное значение состояние ядра.
Это интересно: Как купить Биткоин за рубли максимально выгодно
У видеокарт AMD индекс состояния памяти начинается от параметра «1», который обозначает максимальную экономию, а «2» — это максимально возможная эффективность работы.
Пользователи ферм постоянно выставляют неправильный разгон, завышая этот показатель, и дают слишком малое напряжение на ядро.
Нужно использовать различные индивидуальные настройки и подобрать оптимальный вариант разгона видеоадаптеров для наилучшей эффективной работы.
Самые популярные ошибки при майнинге у карт AMD:
- неправильная прошивка BIOS;
- нехватка напряжения (андервольтинг);
- разные видеокарты в одной сборке.
Реже майнинг может не начаться из-за некорректного сочетания комплектующих фермы.
Архитектура
Hive представляет из себя движок, который превращает SQL-запросы в цепочки map-reduce задач. Движок включает в себя такие компоненты, как Parser(разбирает входящие SQL-запрсоы), Optimimer(оптимизирует запрос для достижения большей эффективности), Planner (планирует задачи на выполнение) Executor(запускает задачи на фреймворке MapReduce.
Для работы hive также необходимо хранилище метаданных. Дело в том что SQL предполагает работу с такими объектами как база данных, таблица, колонки, строчки, ячейки и тд. Поскольку сами данные, которые использует hive хранятся просто в виде файлов на hdfs — необходимо где-то хранить соответствие между объектами hive и реальными файлами.
В качестве metastorage используется обычная реляционная СУБД, такая как MySQL, PostgreSQL или Oracle.
Кто использует систему HiveOS
HiveOS – операционная система для майнинга. Устанавливается она легко, управлять ей может даже новичок.
Плюсы использования HiveOS
- Платформа очень простая, настраивается примерно за 20 минут.
- Понятный интерфейс. Сначала он может показаться запутанным, но уже через полчаса пользования можно быстро понять, где и что находится.
- Поддержка пользователей работает на «отлично».
- Удобно управляется в браузере или через смартфон в приложении. Для работы с воркерами не потребуется ноутбук или ПК.
Существенный минус один – стоимость использования. Первый воркер бесплатен, за каждый последующий на базе видеокарты нужно будет доплатить по $3, за майнинг на ASIC по $2.
Command line interface
Для того чтобы попробовать работу с hive проще всего воспользоваться его командной строкой. Современная утилита для работы с hive называется beeline
(привет нашим партнёрам из одноименного оператора  ) Для этого на любой машине в hadoop-кластере (см. наш туториал по hadoop) с установленным hive достаточно набрать команду. $beeline Далее необходимо установить соединение с hive-сервером: beeline> !connect jdbc:hive2://localhost:10000/default root root Connecting to jdbc:hive2://localhost:10000/default Connected to: Apache Hive (version 1.1.0-cdh5.7.0) Driver: Hive JDBC (version 1.1.0-cdh5.7.0) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000/default> root root — в данном контексте это имя пользователя и пароль. После этого вы получите командную строку, в которой можно вводить команды hive.
) Для этого на любой машине в hadoop-кластере (см. наш туториал по hadoop) с установленным hive достаточно набрать команду. $beeline Далее необходимо установить соединение с hive-сервером: beeline> !connect jdbc:hive2://localhost:10000/default root root Connecting to jdbc:hive2://localhost:10000/default Connected to: Apache Hive (version 1.1.0-cdh5.7.0) Driver: Hive JDBC (version 1.1.0-cdh5.7.0) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000/default> root root — в данном контексте это имя пользователя и пароль. После этого вы получите командную строку, в которой можно вводить команды hive.
Также иногда бывает удобно не вводить sql-запросы в командную строку beeline, а предварительно сохранить и редактировать их в файле, а потом выполнить все запросы из файла. Для этого нужно выполнить beeline с параметрами подключения к базе данных и параметром -f указывающим имя файла, содержащего запросы:
beeline -u jdbc:hive2://localhost:10000/default -n root -p root -f sorted.sql
Установка образа Hive OS на ПК
Чтобы перейти к скачиванию операционной системы и созданию флешки, нужно нажать Download Hive OS на странице hiveos.farm/install. Нужно скачать Zip-архив и разархивировать его на ПК.
На этой же странице внизу предлагается утилита для создания установочной флешки Etcher, нужно перейти по ссылке, после чего появится окно для создания образа с ОС на съемном носителе.
Создание загрузочной флешки
После установки программы и скачивания HiveOS можно приступить к установке. Необходимо выбрать пункт Flash from file на сайте Etcher.
Проследовать простым инструкциям, выбрать сначала разархивированный файл с операционной системой, а за ней флешку, куда будет записан образ. Программа приступит к установке.
Затем необходимо настроить процесс майнинга, создать лог-файл с информацией, и также его скопировать на съемный носитель.
Data Units
При работе с hive можно выделить следующие объекты которыми оперирует hive:
- База данных
- Таблица
- Партиция (partition)
- Бакет (bucket)
Разберем каждый из них подробнее:
База данных
База данных
представляет аналог базы данных в реляционных СУБД. База данных представляет собой
пространство имён
, содержащее таблицы. Команда создания новой базы данных выглядит следующим образом: CREATE DATABASE|SCHEMA Database и Schema в данном контексте это одно и тоже. Необязательная добавка
IF NOT EXISTS
как не сложно догадаться создает базу данных только в том случае если она еще не существует.
Пример создания базы данных:
CREATE DATABASE userdb; Для переключения на соответствующую базу данных используем команду USE: USE userdb;
Таблица
Таблица в hive представляет из себя аналог таблицы в классической реляционной БД. Основное отличие — что данные hive’овских таблиц хранятся просто в виде обычных файлов на hdfs. Это могут быть обычные текстовые csv-файлы, бинарные sequence-файлы, более сложные колоночные parquet-файлы и другие форматы. Но в любом случае данные, над которыми настроена hive-таблица очень легко прочитать и не из hive.
Таблицы в hive бывают двух видов:
Классическая таблица
, данные в которую добавляются при помощи hive. Вот пример создания такой таблицы (источник примера):
CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) COMMENT ‘Employee details’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE; Тут мы создали таблицу, данные в которой будут храниться в виде обычных csv-файлов, колонки которой разделены символом табуляции. После этого данные в таблицу можно загрузить. Пусть у нашего пользователя в домашней папке на hdfs есть (напоминаю, что загрузить файл можно при помощи hadoop fs -put
) файл sample.txt вида: 1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin Загрузить данные мы сможем при помощи следующей команды: LOAD DATA INPATH ‘/user/root/sample.txt’ OVERWRITE INTO TABLE employee; После hive
переместит
данныe, хранящемся в нашем файле в хранилище hive. Убедиться в этом можно прочитав данные напрямую из файла в хранилище hive в hdfs: [[email protected] ~]# hadoop fs -text /user/hive/warehouse/userdb.db/employee/* 1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin Классические таблицы можно также создавать как результат select-запроса к другим таблицам: 0: jdbc:hive2://localhost:10000/default> CREATE TABLE big_salary as SELECT * FROM employee WHERE salary > 40000; 0: jdbc:hive2://localhost:10000/default> SELECT * FROM big_salary; +——————+——————+———————+————————-+—+ | big_salary.eid | big_salary.name | big_salary.salary | big_salary.destination | +——————+——————+———————+————————-+—+ | 1201 | Gopal | 45000 | Technical manager | | 1202 | Manisha | 45000 | Proof reader | +——————+——————+———————+————————-+—+ Кстати говоря, SELECT для создания таблицы в данном случае уже запустит mapreduce-задачу.
Внешняя таблица
, данные в которую загружаются внешними системами, без участия hive. Для работы с внешними таблицами при создании таблицы нужно указать ключевое слово
EXTERNAL
, а также указать путь до папки, по которому хранятся файлы:
CREATE EXTERNAL TABLE IF NOT EXISTS employee_external ( eid int, name String, salary String, destination String) COMMENT ‘Employee details’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE LOCATION ‘/user/root/external_files/’; После этого таблицей можно пользоваться точно так же как и обычными таблицами hive. Самое удобное в этом, что вы можете просто скопировать файл в нужную папочку в hdfs, а hive будет автоматом подхватывать новые файлы при запросах к соответствующей таблице. Это очень удобно при работе например с логами.
Партиция (partition)
Так как hive представляет из себя движок для трансляции SQL-запросов в mapreduce-задачи, то обычно даже простейшие запросы к таблице приводят к полному сканированию данных в этой таблицы. Для того чтобы избежать полного сканирования данных по некоторым из колонок таблицы можно произвести партиционирование этой таблицы. Это означает, что данные относящиеся к разным значениям будут физически храниться в разных папках на HDFS.
Для создания партиционированной таблицы необходимо указать по каким колонкам будет произведено партиционирование:
CREATE TABLE IF NOT EXISTS employee_partitioned ( eid int, name String, salary String, destination String) COMMENT ‘Employee details’ PARTITIONED BY (birth_year int, birth_month string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE; При заливке данных в такую таблицу необходимо явно указать, в какую партицию мы заливаем данные: LOAD DATA INPATH ‘/user/root/sample.txt’ OVERWRITE INTO TABLE employee_partitioned PARTITION (birth_year=1998, birth_month=’May’); Посмотрим теперь как выглядит структура директорий: [[email protected] ~]# hadoop fs -ls /user/hive/warehouse/employee_partitioned/ Found 1 items drwxrwxrwx — root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998 [[email protected] ~]# hadoop fs -ls -R /user/hive/warehouse/employee_partitioned/ drwxrwxrwx — root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998 drwxrwxrwx — root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998/birth_month=May -rwxrwxrwx 1 root supergroup 161 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998/birth_month=May/sample.txt Видно, что структура директорий выглядит таким образом, что каждой партиции соответствует отдельная папка на hdfs. Теперь, если мы будем запускать какие-либо запросы, у казав в условии WHERE ограничение на значения партиций — mapreduce возьмет входные данные только из соответствующих папок.
В случае External таблиц партиционирование работает аналогичным образом, но подобную структуру директорий придется создавать вручную.
Партиционирование очень удобно например для разделения логов по датам, так как правило любые запросы за статистикой содержат ограничение по датам. Это позволяет существенно сократить время запроса.
Бакет
Партиционирование помогает сократить время обработки, если обычно при запросах известны ограничения на значения какого-либо столбца. Однако оно не всегда применимо. Например — если количество значений в столбце очень велико. Напрмер — это может быть ID пользователя в системе, содержащей несколько миллионов пользователей.
В этом случае на помощь нам придет разделение таблицы на бакеты. В один бакет попадают строчки таблицы, для которых значение совпадает значение хэш-функции вычисленное по определенной колонке.
При любой работе с бакетированными таблицами необходимо не забывать включать поддержку бакетов в hive (иначе hive будет работать с ними как с обычными таблицами):
set hive.enforce.bucketing=true; Для создания таблицы разбитой на бакеты используется конструкция CLUSTERED BY set hive.enforce.bucketing=true; CREATE TABLE employee_bucketed ( eid int, name String, salary String, destination String) CLUSTERED BY(eid) INTO 10 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE; Так как команда Load используется для простого перемещения данных в хранилище hive — в данном случае для загрузки она не подходит, так как данные необходимо предобработать, правильно разбив их на бакеты. Поэтому их нужно загрузить при помощи команды INSERT из другой таблицы(например из внешней таблицы): set hive.enforce.bucketing=true; FROM employee_external INSERT OVERWRITE TABLE employee_bucketed SELECT *; После выполнения команды убедимся, что данные действительно разбились на 10 частей: [[email protected] ~]# hadoop fs -ls /user/hive/warehouse/employee_bucketed Found 10 items -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000000_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000001_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000002_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000003_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000004_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000005_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000006_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000007_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000008_0 -rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000009_0 Теперь при запросах за данными, относящимися к определенному пользователю, нам не нужно будет сканировать всю таблицу, а только 1/10 часть этой таблицы.
Главная
Блокчейн Hive — один из блокчейнов, появившихся в 2022 году. Он перешел в свою собственную сеть после того, как был разветвлен из блокчейна Steem в марте 2022 года. Это был один из самых противоречивых форков 2022 года, потому что основатель Tron Джастин Сан
сыграл большую роль в этом форке. В этой статье мы рассмотрим общую информацию о Hive, областях его использования и возможностях распространения.
Основная причина, по которой Hive покинула блокчейн Steem, заключалась в создании децентрализованного и социального блокчейна. Бывшие пользователи Steem думали, что Tron и основатель Tron Джастин Сан
взял на себя и институционализировал Steem. Платформа Hive выделяется тем, что является социальным блогом и содержит вознаграждения в криптовалютах. Кроме того, на платформе используются децентрализованные приложения, а интеллектуальные медиа-токены (SMT) используются в качестве средства обмена.
На платформе Hive пользователи могут публиковать свои собственные статьи, и эти статьи не могут быть подвергнуты цензуре. Любые создатели контента зарабатывают токены HIVE собственной криптовалюты Hive на основе контента, который они создают. Награды улья распределяются с помощью жетонов, которые появляются в результате определенной инфляции.
При желании пользователи могут конвертировать свои токены HIVE в Hive Power. Это то же самое, что и стейкинг. Благодаря Hive Power пользователи могут получать регулярный доход и иметь больший контроль над своими сообщениями.
В то же время токены HIVE можно использовать для голосования за принятие решений о блокчейне. В отличие от Steem, Hive требует, чтобы поставленные токены оставались в сети не менее 30 дней. Таким образом, отложенные решения предотвращают любую попытку взлома системы.
С тех пор, как был создан блокчейн Steem, почти наверняка случился крупный хард-форк. Потому что изначально разработчики каким-то образом добыли 80% своих токенов STEEM. Таким образом, другие пользователи не могли майнить. Таким образом, блокчейн Steem был переведен на консенсус DPoS. Первые создатели отреагировали на это довольно быстро. Однако в компании Steem заверили, что добытые токены будут потрачены на разработку, и выпуск был частично закрыт.
Эта атмосфера доверия просуществовала около 4 лет. Но буря разразилась, когда в феврале 2022 года Tron Foundation приобрела Steemit Inc. Ранее упомянутые добытые токены перешли к Tron. Tron использовал эти токены, чтобы влиять на управление блокчейном. Вещи начинали накаляться. Сообщество Steem приняло меры, чтобы заблокировать доступ Tron к добытым токенам и заблокировать токены. Для этого был сделан софт-форк с голосованием. Однако, согласно утверждениям, Tron удалось перемотать этот софт-форк, поскольку у него хорошие отношения с биржами, на которых хранится большое количество STEEM.
В результате сообщество нашло решение проблемы хард-форка, и подготовка была начата. Многие пользователи думали, что Steem теперь находится в руках Tron. Таким образом, 20 марта 2022 года родился блокчейн Hive.
Во время хард-форка блокчейн Hive в точности скопировал блокчейн Steem. Таким образом, весь контент был перенесен на платформу Hive. В то же время эти учетные записи также были скопированы, и HIVE был распределен путем сброса количества токенов STEEM на учетные записи. Однако учетные записи, принадлежащие Steemit Inc, хранились отдельно от этого события миграции. Таким образом, 80% добытых токенов не были перераспределены.
Многие пользователи, которые были активны на Steem и перешли на Hive, начали продавать токены STEEM. Обычно события должны были быть прекращены после хард-форка, но этого не произошло.
Управляющий трекер Hive обнаружил, что несколько аккаунтов действовали в интересах Трона. Ходят слухи, что эти аккаунты занесены в черный список Hive. Однако известно, что узлы, на которых запущен хард-форк Tron, не могут получить разрешение на создание блоков Hive. В ответ Трон конфисковал 20 сторонников Улья из токенов Steem узла. Steem утверждал, что этот шаг был сделан для предотвращения враждебных действий. Эти конфликты не коснулись обычных пользователей. Они могли войти в свои учетные записи с обеих сторон или использовать любую платформу по своему желанию.
Hive, как и Steem, продолжает модель DPoS. В этой системе пользователи могут выбирать свидетелей (разновидность узлов). Выбранные свидетели имеют право голоса в зависимости от получаемой ими поддержки.
Кроме того, Hive имеет следующие особенности:
— Блоки могут быть изготовлены за 3 секунды. — Комиссионные за транзакции устранены. — Сеть получает высокое масштабирование. — Можно создать личный кошелек и имена учетных записей. — Емкость условного депонирования. — Включает систему вознаграждений для социальных сетей.
Блокчейн Hive отличается от Steem несколькими ключевыми моментами:
— Блокчейн Hive не включает 80% от общего количества добытых ранее токенов, как в случае со Steem. — Разработчики предусмотрели 30-дневный кулдаун для новых действий по ставкам, чтобы предотвратить атаки поглощения. — В новой системе другие действия не действуют во время 30-дневного восстановления Hive. Предполагается, что в будущем будет больше изменений в руководстве.
У Hive есть основная платформа под названием hive.blog. Однако он доступен пользователям на другой платформе под названием Peakd. Платформа Peakd занимает очень важное место, поскольку позволяет размещать на платформе сторонние децентрализованные приложения. Эти децентрализованные приложения были все более распространены на Steem до хард-форка. На платформе Steem существует около 100 децентрализованных приложений. Среди наиболее заметных — YouTube-подобный Dtube, Instagram-подобная платформа APPICS и карточная игра Steem Monster от Steem.
После апреля 2022 года около 20 приложений были перенесены из Steem в Hive. Одним из них был карточный файтинг Splinterlands. Splinterlands был одним из самых популярных приложений на Steem. Был создан веб-сайт hiveprojects.io, содержащий общую информацию о децентрализованных приложениях. Согласно этому списку, в настоящее время на платформе Hive имеется более 50 децентрализованных приложений.
Checklist по использованию hive
Теперь мы разобрали все объекты, которыми оперирует hive. После того как таблицы созданы — можно работать с ними, так как с таблицами обычных баз данных. Однако не стоит забывать о том что hive — это все же движок по запуску mapreduce задач над обычными файлами, и полноценной заменой классическим СУБД он не является. Необдуманное использование таких тяжелых команд, как JOIN может привести к очень долгим задачам. Поэтому прежде чем строить вашу архитектуру на основе hive — необходимо несколько раз подумать. Приведем небольшой checklist по использованию hive:
- Данных которые надо обрабатывать много и они не влазят на диск одной машины (иначе лучше подумать над классическими SQL-системами).
- Данные в основном только добавляются и редко обновляются (если обновления часты — возможно стоит подумать об использовании Hbase например, см наш предыдущий материал.
- Данные имеют хорошо структурированную структуру и хорошо разбиваются на колонки.
- Паттерны обработки данных хорошо описываются декларативным языком запросов (SQL).
- Время ответа на запрос не критично(так как hive работает на основе MapReduce — интерактивности ждать не стоит).
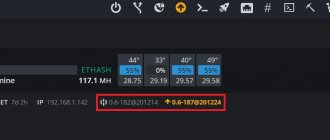
Как управлять ригом через сайт hiveos.farm
В верхней панели экрана в веб-интерфейсе на сайте Hive OS находится панель управления, в ней каждая кнопка отвечает за конкретный параметр работы.
Чтобы увидеть панель, нужно зайти в созданный ранее воркер, нажав по нему на главной странице сайта, а затем выбрать риг.
Здесь можно управлять питанием, настроить подключение к интернету, запускать и работать с майнером, контролировать температуру или использовать вотчдог.
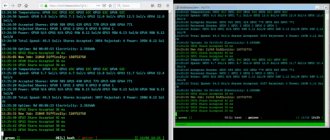
Важный пункт меню – Remote Access или Удаленный доступ.
Нужно нажать на Hive Shell Start, подождать пока формируется специальная ссылка для входа.
Находится она в левом углу экрана в разделе Hive Shell.
В загруженной консоли нужно прописать команду miner.
Запустится консоль майнера, которая показывает все важные детали. Например, эффективный хешрейт, температуры и другую важную информацию, требующуюся в процессе майнинга.
Проверка работы
Если майнинг был запущен в сети ETH, то можно зайти на сайт ethermine.org. В строке поиска вверху возле оранжевой кнопки необходимо прописать адрес, куда добываются монеты.
В панели указана вся важная информация, сколько добывается в день или неделю, вся невыплаченная прибыль, хешрейт.
В первое время статистика не будет отвечать действительности, нужно подождать от 2 до 3 часов. После этого цифры будут верны.
В настройках на третьей вкладке Settings можно указать e-mail. На него будут приходить важные оповещения, если вдруг майнинг прекратится.
Там же можно указать, когда будут отправляться выплаты. Минимальное значение – 0.05 ETH.
Приложение
У Hive OS есть приложение, в нем есть все функции десктопной версии. Управлять ригами для майнинга можно с телефона.
Hive OS одна из лучших операционных систем для майнинга. Она удобна в использовании, контролировать процесс можно через сайт платформы или с мобильного приложения.
Регистрация, первое подключение и настройка очень просты, потребуется всего полчаса, чтобы настроить работу майнингового рига и начать зарабатывать на добыче криптовалюты.
Особенности улья
- В рабочем интерфейсе используется синтаксис, подобный SQL, чтобы обеспечить возможности быстрой разработки и простоту использования.
- Избегайте написания MapReduce и сократите затраты разработчиков на обучение
- Единое управление метаданными, может делиться метаданными с impala / spark и т. Д.
- Простота расширения, HDFS + MapReduce позволяет увеличивать размер кластера и поддерживать пользовательские функции.
- Автономная обработка данных: например, анализ журналов, автономный анализ массивных структурированных данных
- Задержка выполнения Hive относительно высока, поэтому hihve часто используется в случаях, когда требования к реальному времени невысоки.
- Преимущество Hive заключается в обработке больших данных, но не имеет преимущества при обработке небольших данных, поэтому задержка выполнения Hive относительно высока.
Базовое введение в HIVE
Hive — это открытый исходный код от FaceBook, предназначенный для сбора статистики данных в массивных структурированных журналах, который позже стал проектом Apache Hive с открытым исходным кодом. Hive — это инструмент хранилища данных на основе Hadoop, который может отображать файлы структурированных данных в таблицу и предоставлять SQL-подобная (также известная как HQL) функция запроса, ее суть заключается в преобразовании HQL в программу MapReduce, гибкость и масштабируемость лучше, поддержка пользовательских функций (UDF), пользовательский формат хранения для обработки и хранения данных, но потому что Его временная задержка больше, подходит для автономной обработки данных.